

Abstract
Human Motion Recovery (HMR) research mainly focuses on ground-based motions such as running. The study on capturing climbing motion, an off-ground motion, is sparse. This is partly due to the limited availability of climbing motion datasets, especially large-scale and challenging 3D labeled datasets. To address the insufficiency of climbing motion datasets, we collect AscendMotion, a large-scale well-annotated, and challenging climbing motion dataset. It consists of 412k RGB, LiDAR frames, and IMU measurements, including the challenging climbing motions of 22 skilled climbing coaches across 12 different rock walls. Capturing the climbing motions is challenging as it requires precise recovery of not only the complex pose but also the global position of climbers. Although multiple global HMR methods have been proposed, they cannot faithfully capture climbing motions. To address the limitations of HMR methods for climbing, we propose ClimbingCap, a motion recovery method that reconstructs continuous 3D human climbing motion in a global coordinate system. One key insight is to use the RGB and LiDAR modalities to separately reconstruct motions in camera coordinates and global coordinates and to optimize them jointly. We demonstrate the quality of the AscendMotion dataset and present promising results from ClimbingCap.
Introduction
Global Human Motion Recovery (HMR) is challenged by complex human poses and their environmental interactions, requiring consistency in world coordinates for authenticity and feasibility. Existing methods estimate poses from RGB images, e.g., SPIN, DeepCap, LiDAR point clouds, e.g., LiDARCap, and IMUs, e.g., DIP, primarily focusing on ground-based motions like running and dancing. Climbing, an off-ground activity central to an Olympic sport, involves unique dynamics but lacks sufficient research and datasets. Only SPEED21 (2D) and CIMI4D (3D, basic motions) are available, both limited in scale.
We introduce AscendMotion, a large-scale, multi-modal dataset of 22 skilled climbers on 12 rock walls, featuring synchronized RGB, LiDAR, and IMU data with global trajectories. Capturing climbing motion is complex due to human-scene interactions and global localization needs. Current HMR methods, optimized for ground-based RGB data, struggle with coordinate ambiguities and error accumulation in climbing scenarios.
To address this, we propose ClimbingCap, an HMR method reconstructing 3D climbing motion in camera and global coordinates using separate decoding, post-processing, and semi-supervised training. Our contributions are:
- AscendMotion: A comprehensive dataset exceeding prior resources.
- ClimbingCap: A multi-modal HMR method for climbing.
- Validation: Experiments showing superior performance over state-of-the-art methods.
Method: ClimbingCap
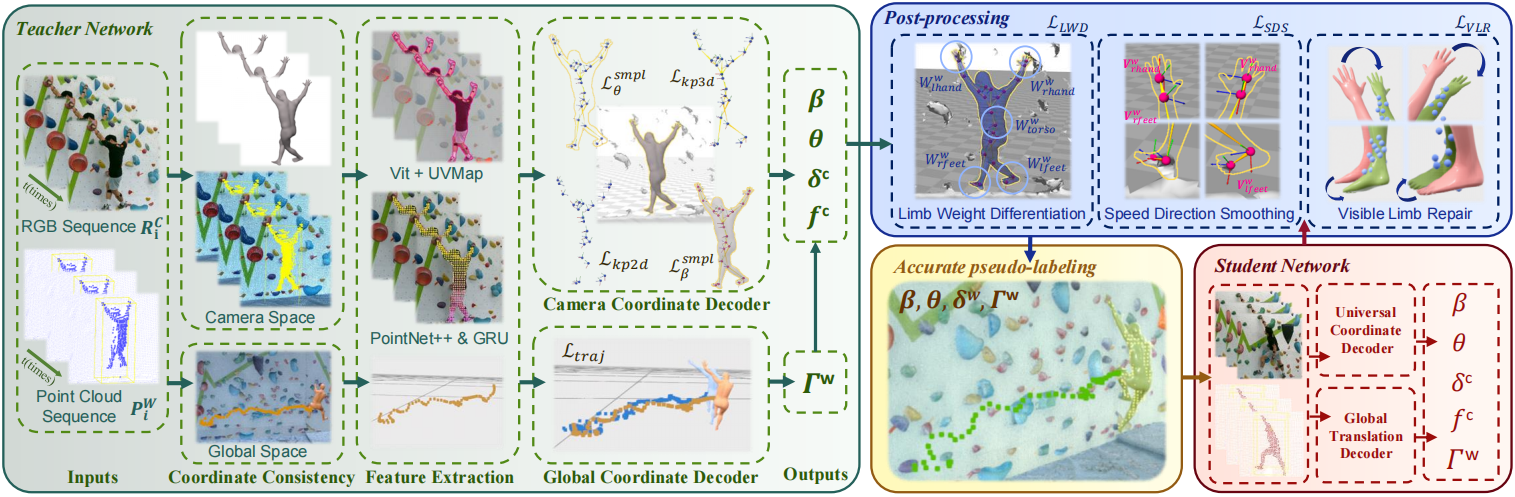
Climbing motion capture is complex, involving extreme poses and full-body exertion, requiring precise alignment with the rock wall in world coordinates. The ClimbingCap pipeline comprises three stages: separate coordinate decoding, post-processing, and semi-supervised training, addressing off-ground dynamics and scene interactions while leveraging unlabeled data.
Separate Coordinate Decoding
The Separate Coordinate Decoding (SCD) stage processes RGB sequences and LiDAR point clouds to predict poses in camera coordinates and positions in global coordinates. RGB images and transformed point cloud data (via extrinsic matrix P_c = Ω_w2c · P_w) are fed into feature extraction modules (based on ViT and PointNet++) to obtain visual and geometric features. These drive two decoders:
Camera Coordinate Decoder: Uses RGB and point cloud features to iteratively optimize SMPL parameters (pose θ, shape β, translation ∆c) in camera coordinates via T_Decoder. Global Coordinate Decoder: Predicts global translation parameters (Γ_trans) to capture motion trajectories in world coordinates.
The loss function combines 3D keypoint loss (L_kp3d), 2D keypoint loss (L_kp2d), SMPL parameter loss (L_smpl), and global trajectory loss (L_traj):
L = L_kp3d + L_kp2d + L_smplθ + L_smplβ + L_traj.
Post-processing
This stage refines SCD outputs, leveraging LiDAR’s 3D world-coordinate data to transform poses via Ω^−1_w2c. It optimizes poses using three losses: L_LWD (weighted vertex optimization), L_SDS (joint smoothing), and L_VLR (limb-end refinement), applied with the Adam optimizer.
Semi-supervised Training
Labeled climbing data is scarce, but unlabeled data from AscendMotion is abundant. Using a teacher-student framework, the teacher model (post-SCD and post-processing) generates pseudo-labels from unlabeled data to train the student model, enhancing HMR performance.
The AscendMotion Dataset
To enhance Human Mesh Recovery (HMR) research for climbing in global coordinates, we present AscendMotion, a dataset capturing complex rock climbing motions on non-planar surfaces. It features multi-modal data from 22 skilled climbers across 12 real-world scenes, performing bouldering, speed, and lead climbing. The dataset includes 344 minutes of labeled and 441 minutes of unlabeled data, recorded with synchronized IMU, RGB cameras, and LiDAR.
Hardware and Configuration
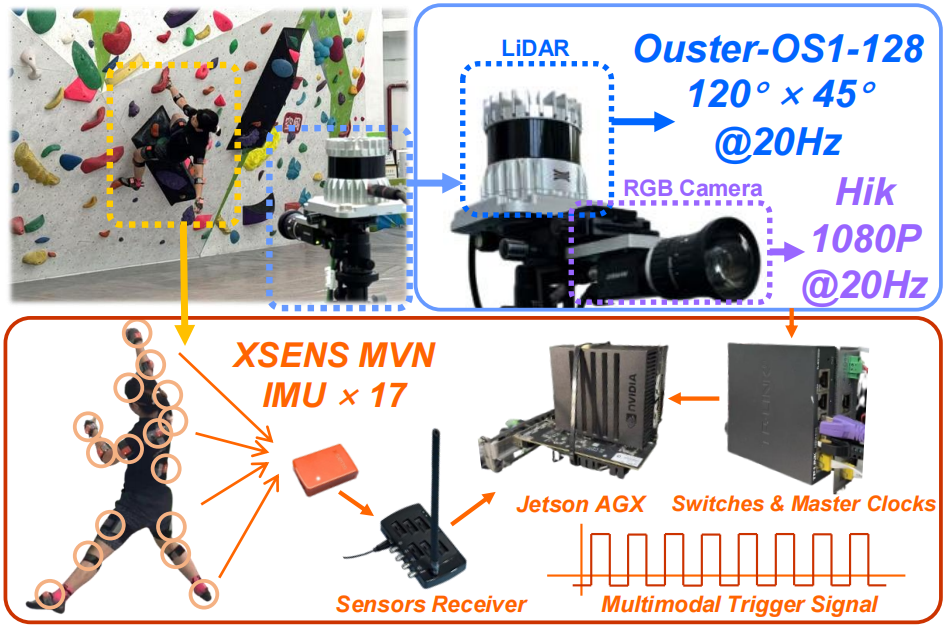
AscendMotion integrates LiDAR (Ouster-OS1, 20 FPS), RGB cameras (Hik 1080P, 20 FPS), and a Trimble X7 scanner (~80M points/scene). Labeled data uses Xsens MVN (17 IMUs, 60 FPS) for climbers, while unlabeled data relies on RGB and LiDAR. Motion is represented as M = (T, θ, β), with T as global translation, θ as SMPL pose, and β as shape from IPNet.
Annotation Pipeline
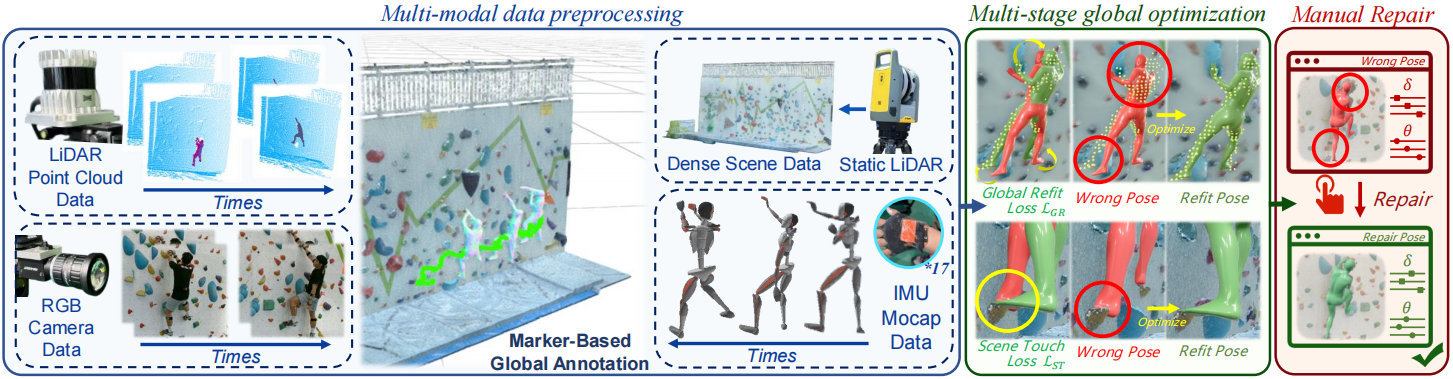
The pipeline refines IMU-derived T and θ via preprocessing, multi-stage optimization, and manual annotation.
Multi-modal Data Preprocessing: Time Synchronization: RGB and LiDAR are synced via PTP; IMU is post-aligned with anchor frames. Calibration: LiDAR defines world coordinates; IMU data is transformed, and RGB-LiDAR-IMU are frame-calibrated.
Multi-stage Global Optimization: Initial T and θ from IMU are optimized using: Global Refit Loss (L_GR): Aligns SMPL vertices V to point clouds P via modified Chamfer distance, prioritizing torso and limb fit (d_limb ≤ d_torso). Scene Touch Loss (L_ST): Prevents SMPL-scene intersections by penalizing penetration depth (η(v_i) = (v_i − q_j) · n_j).
Manual Annotation and Verification: Four observers refine auto-annotations using an SMPL tool, adjusting ambiguous limb poses in RGB views and propagating key frames for consistency.
AscendMotion Dataset Gallery
Experiments
This section presents an evaluation of the AscendMotion optimization process, demonstrates the challenges posed by the AscendMotion dataset for existing Human Mesh Recovery (HMR) methods, and assesses ClimbingCap along with multiple HMR approaches in climbing motion datasets. Additionally, an ablation study highlights the contribution of each component in ClimbingCap. Details on the experimental setup and metrics are provided in the supplementary material.
Dataset Evaluation
To assess the annotation quality of AscendMotion, we categorize the dataset into horizontal and vertical rock wall scenes and evaluate the performance of the global optimization stage by comparing automated annotations with manually annotated ground truth. The evaluation employs standard metrics, including Mean Per Joint Position Error (MPJPE), Procrustes Aligned MPJPE (PA-MPJPE), Per Vertex Error (PVE), and acceleration error (Accel, in m/s²).
An ablation study examines the effect of different constraints in the optimization stage, focusing on L_ST and L_GR losses. The results indicate that error metrics remain low, confirming the effectiveness of the global optimization pipeline and the high annotation quality of AscendMotion.
Comparison of Global Motion Recovery

We assess global HMR performance by following established motion evaluation protocols. Consistent with WHAM, we compute world coordinate MPJPE metrics by segmenting predicted global sequences into 100-frame segments. These segments are aligned with ground truth either across the entire segment (WA-MPJPE) or the first two frames (W-MPJPE). Additional metrics include Root Translation Error (RTE), motion jitter (Jitter, in m/s³), and relative global translation error (T-Error, in meters).
Qualitative Experiments for ClimbingCap
Conclusion
We propose AscendMotion, a large-scale and multi-modal climbing motion dataset, and ClimbingCap, a human motion recovery framework for climbing motions. AscendMotion surpasses previous climbing datasets in both scale and complexity. ClimbingCap effectively recovers 3D climbing motions in the global coordinate system, ensuring accurate pose estimation and global localization. Experimental results demonstrate that ClimbingCap outperforms existing methods in accuracy and robustness.
Citation
@inproceedings{yan2025climbingcap,
title={ClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate},
author={Yan, Ming and Lin, Xincheng and Luo, Yuhua and Fan, Shuqi and Dai, Yudi and Zhong, Qixin and Zhong, Lincai and Ma, Yuexin and Xu, Lan and Wen, Chenglu and others},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={12312--12323},
year={2025}
}