Abstract
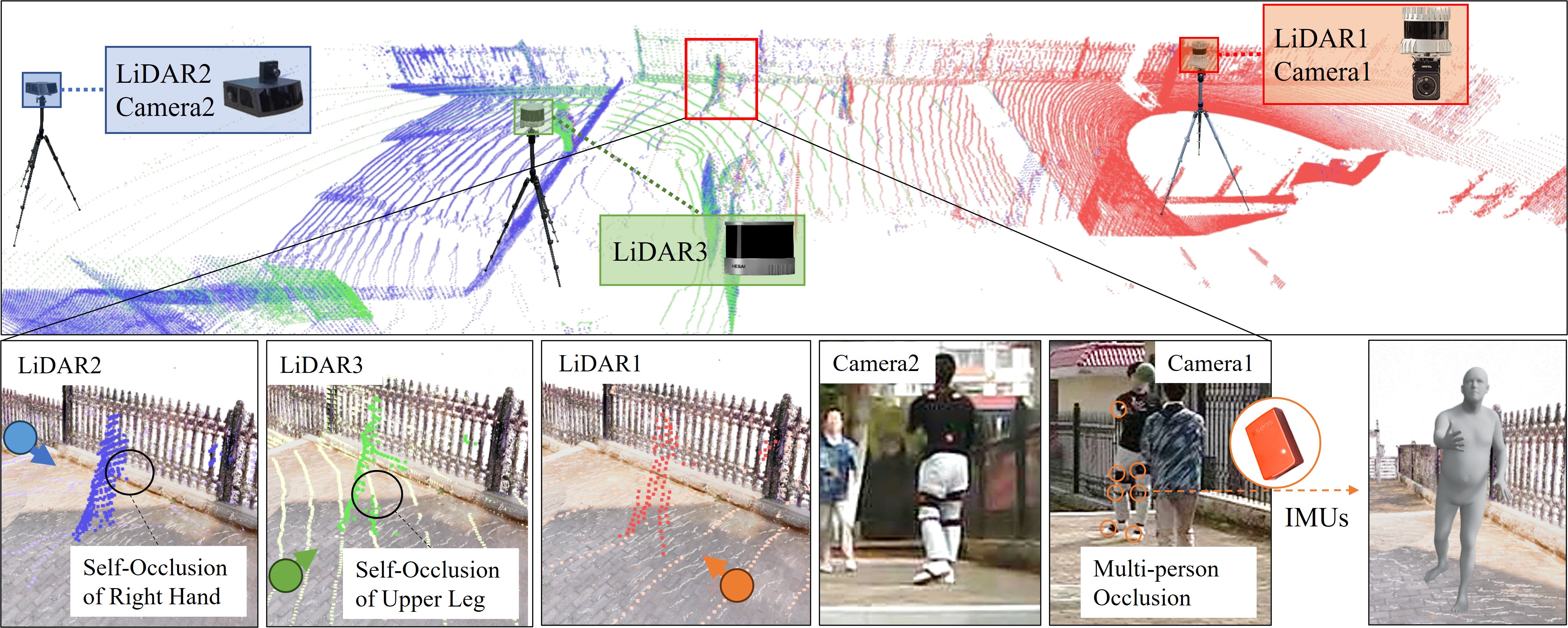
LiDAR-involved 3D Human Pose Estimation (HPE) has received increasing attention recently. However, existing LiDAR-involved HPE datasets pay less attention to occlusion, and only feature on one viewport. This limited scope of dataset considerably hinders the variability of data and limits the generalization capabilities of HPE methods, especially in occlusion scenarios. To bridge this gap, we introduce ViLi, an occlusion-aware 3D human mocap dataset from multi-view LiDAR and camera. Our dataset contains around 631K frames of human body point clouds from 13 performers captured by three types of LiDAR sensors in different viewports. Multi-view cameras and IMUs are deployed to record RGB videos and human poses. Benefiting from multi-view LiDAR, we introduced a human motion optimization method to acquire the trajectory of performers and further improve the motion annotations from raw IMUs. Quantitative and qualitative experiments demonstrate that different viewports, various occlusion scenarios, and rich LiDAR sensor types benefit the current HPE methods. We hope the release of ViLi will contribute to advancements in occlusion-aware 3D HPE and help bridge the domain gap induced by different LiDAR sensors for 3D HPE.
ViLi Visualization
We sequentially present three human motion sequences: Bouncy ball, Badminton and Football. In each motion sequence segment, we select the best viewport and display synchronized point cloud data and RGB video from correspondent LiDAR and Camera, and human SMPL mesh data optimized by our methods.
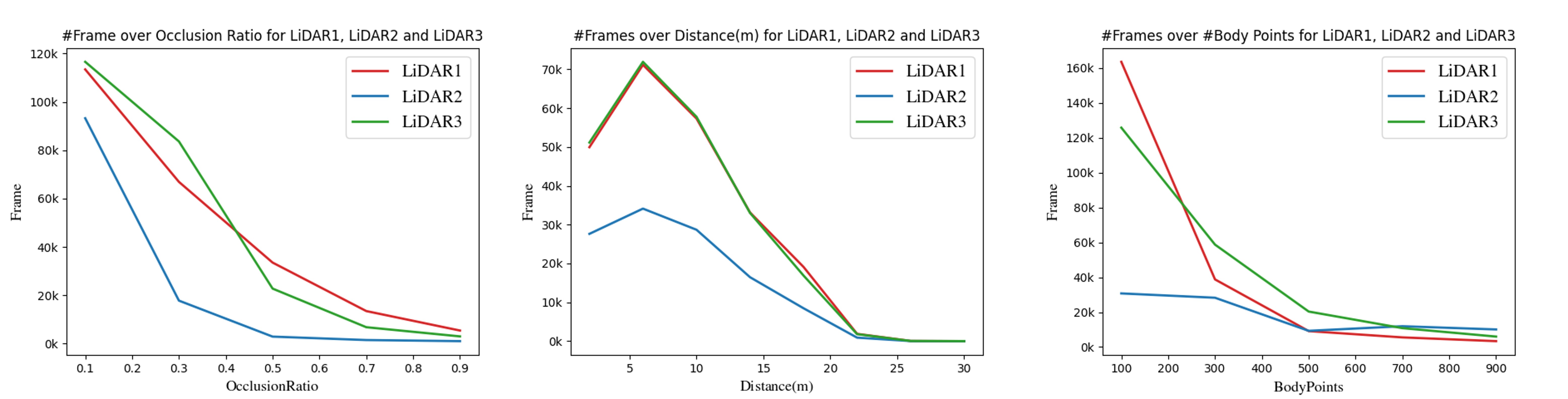
Statistics of ViLi Dataset