

Abstract
Humanoid robots have achieved significant progress in motion generation and control, exhibiting movements that appear increasingly natural and human-like. Inspired by the Turing Test, we propose the Motion Turing Test, a framework that evaluates whether human observers can discriminate between humanoid robot and human poses using only kinematic information. To facilitate this evaluation, we present the Human-Humanoid Motion (HHMotion) dataset, which consists of 1,000 motion sequences spanning 15 action categories, performed by 11 humanoid models and 10 human subjects. All motion sequences are converted into SMPL-X representations to eliminate the influence of visual appearance. We recruited 30 annotators to rate the human-likeness of each pose on a 0-5 scale, resulting in over 500 hours of annotation. Analysis of the collected data reveals that humanoid motions still exhibit noticeable deviations from human movements, particularly in dynamic actions such as jumping, boxing, and running. Building on HHMotion, we formulate a human-likeness evaluation task that aims to automatically predict human-likeness scores from motion data. Despite recent progress in multimodal large language models, we find that they remain inadequate for assessing motion human-likeness. To address this, we propose a simple baseline model and demonstrate that it outperforms several contemporary LLM-based methods. The dataset, code, and benchmark will be publicly released to support future research in the community.
Introduction
Humanoid robot motion has seen significant progress, while evaluating its human-likeness remains subjective and lacks standardized metrics. Existing benchmarks primarily focus on stability and task success in generation (e.g., HumanPlus) and control (e.g., HumanMimic), often overlooking the subtle kinematic nuances that distinguish robot movement from human motion. To bridge this gap, inspired by the Turing Test, we propose the Motion Turing Test, a framework to evaluate whether humanoid motions are indistinguishable from human ones based purely on kinematic information, independent of visual appearance.
We introduce HHMotion, a large-scale dataset featuring 1,000 motion sequences across 15 categories, captured from 11 state-of-the-art humanoid robots and 10 human subjects. By converting all sequences into SMPL-X representations, we eliminate appearance bias, allowing 30 annotators to provide over 500 hours of human-likeness scoring. Our analysis reveals that while robots excel in simple gait, they still exhibit noticeable deviations in dynamic actions like boxing and running.
To automate this evaluation, we propose PTR-Net, a Pose-Temporal Regression baseline that outperforms contemporary Vision-Language Models (VLMs) in predicting human-likeness scores. Our contributions are:
-
Motion Turing Test: A novel, motion-centered evaluation framework for humanoid robots.
-
HHMotion Dataset: The first comprehensive dataset providing human-likeness ratings for human and humanoid motions.
-
PTR-Net: A simple yet robust baseline for quantitative human-likeness regression, serving as a potential reward model for RL-based motion synthesis.
Human-humanoid Motion Dataset
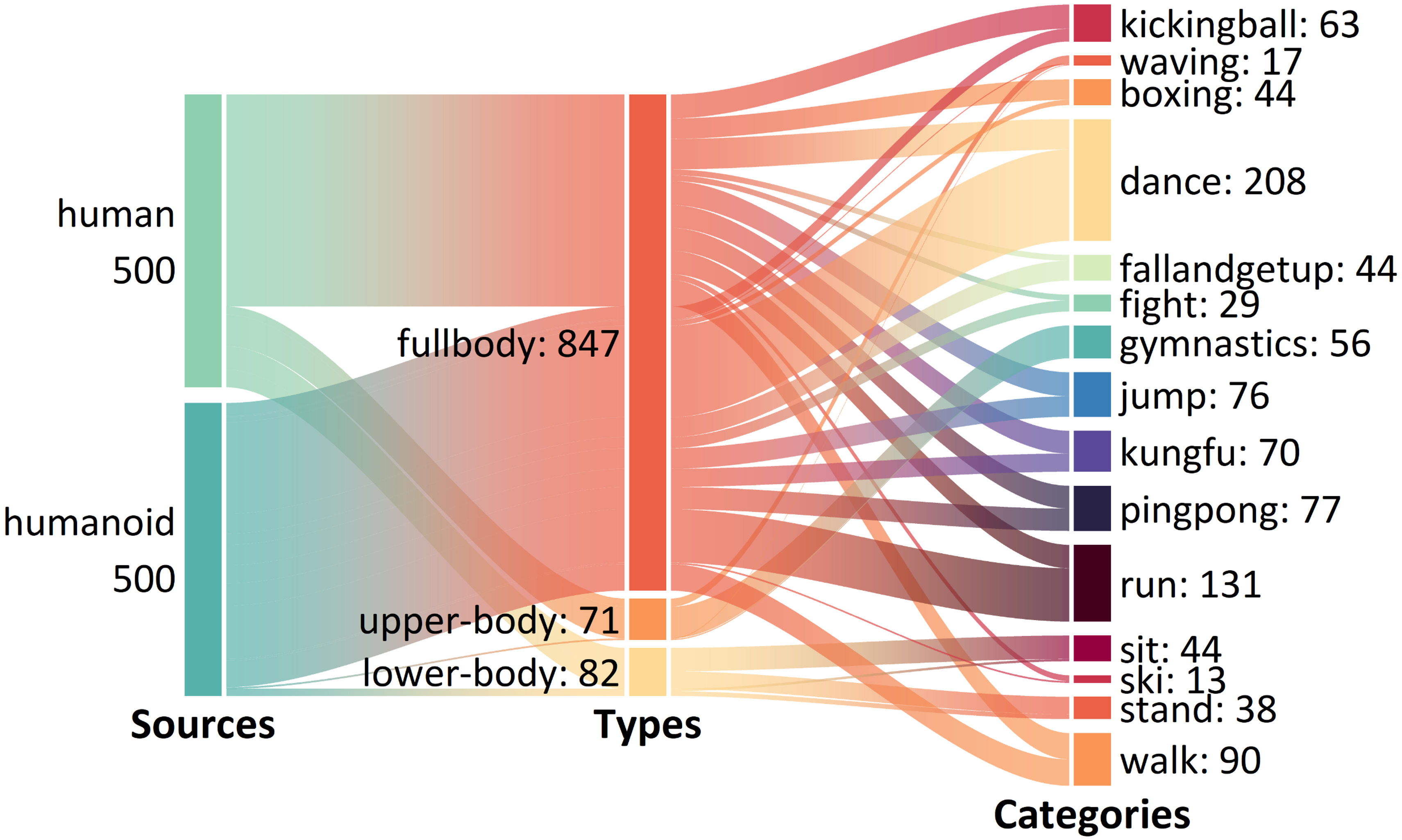
HHMotion covers a wide range of 15 action categories, 11 humanoid robot models and 10 subjects performing actions in the same category as robots. Moreover, to increase the dataset’s diversity, we collected multiple human motion videos from YouTube (see detailed dataset sources and humanoid models in Supplementary File). Each video is standardized into a 5-second clip, resulting in 1,000 motion clips. Each motion clip is scored by human annotators on a Likert scale of 0 to 5. 0 represents “complete robotic,” whereas 5 represents “complete human-like”.
Data Construction
To ensure that our Motion Turing Test focuses purely on motion rather than appearance, we adopt a pose-level strategy that converts all videos into the SMPL-X model, ensuring that only motion information is focused for evaluation.
Robot Data: Collected from international robotics conferences such as WRC, WAIC, and WHRG, combined with data from simulated environments (LAFANI Retargeting Dataset), a total of 500 high-quality robot motion segments.
Human Data: Corresponding to the robot motions, 500 human motion segments have been collected, including recordings from volunteers and internet videos. Additionally, a subset of human “imitating robot” motions is specifically included to increase the challenge of evaluation.
Human-humanoid Pose Estimation
To convert videos into a unified SMPL-X model, we compared various mainstream methods for human pose estimation (HPE) and robot pose estimation (RPE). Due to the poor generalizability of robot-specific estimators across different robot models, a more robust general-purpose HPE method GVHMR, which proved effective for both humans and robots, was ultimately adopted to generate a unified motion representation.
Human Scoring Pipeline

Scoring Rules for Human-likeness Evaluation
To quantitatively evaluate the human-likeness of the motions, we invited 30 annotators to rate 1,000 motion clips.
Rating Scale: A 0-5 Likert scale was used. A score of 0 represents completely robotic, with no human characteristics. A score of 5 represents motions that are completely indistinguishable from human actions.
Quality Assurance: To ensure the credibility of the ratings, we implemented a rigorous Inter-Annotator Consistency (IAC) check, excluding inconsistent rating results.
Analysis of Rating Data
Analysis of the annotated data reveals several key findings. Despite notable advancements in humanoid robotics, humans remain capable of easily distinguishing between robot and human motions. The disparity is most pronounced in dynamic actions that require high-frequency coordination and rapid transitions such as jumping and boxing, where the score gaps between robots and humans are largest. In contrast, cyclical motions like walking and standing receive relatively closer ratings. Furthermore, the data indicate that robot motion performance in simulated environments generally surpasses that observed in real-world settings.
PTR-Net: A Simple Baseline
Network architecture
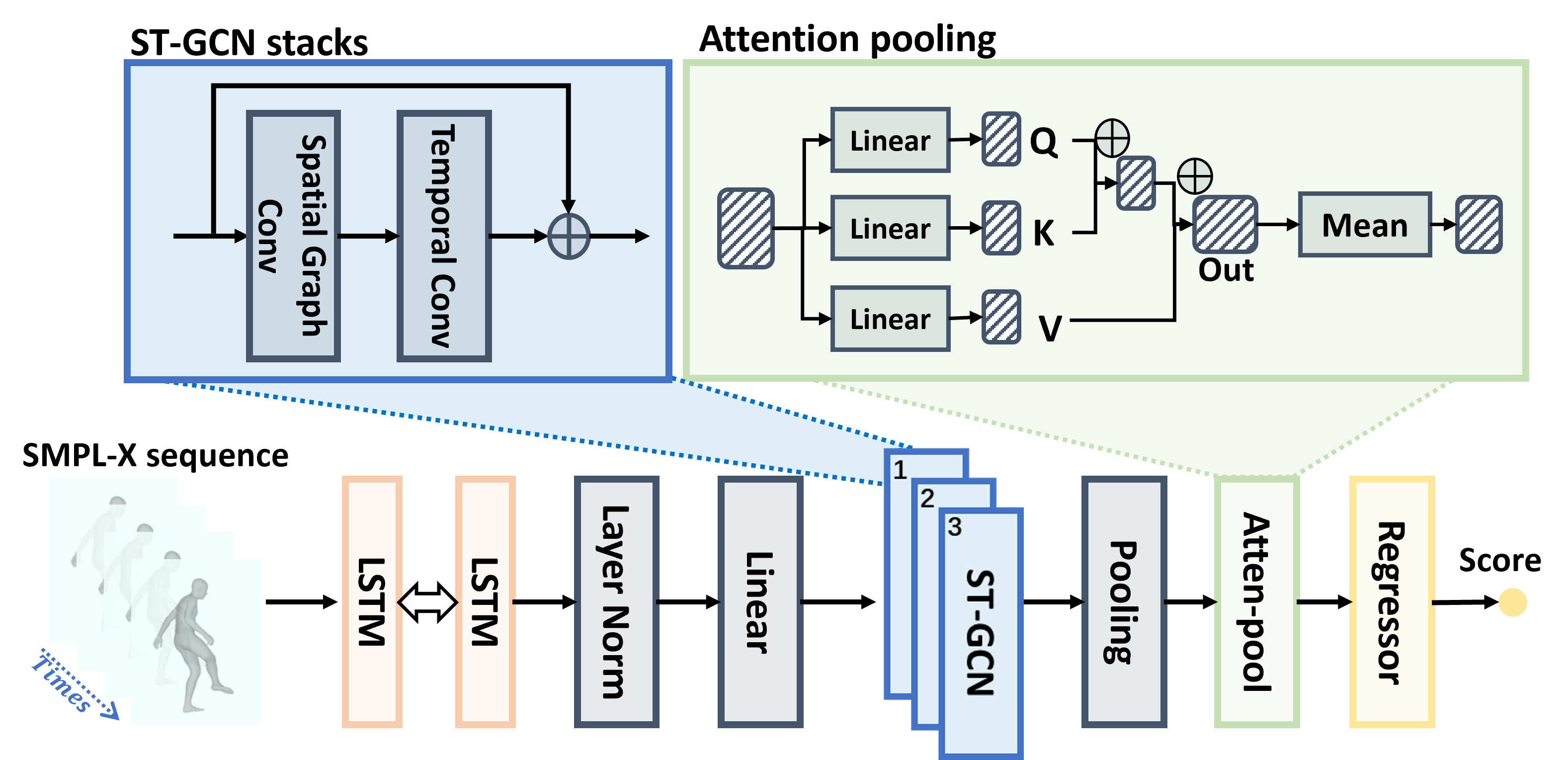
Our proposed PTR-Net baseline consists of a temporal encoder, spatial-temporal graph convolution, and attention pooling, then uses a score regressor to predict the human-likeness score.
Temporal Encoder: Employs a two-layer bidirectional LSTM to capture long-range temporal dependencies.
Spatial-Temporal Graph Convolutional Network: Processes SMPL-X pose sequences represented as graphs by stacking ST-GCN blocks, which alternate between spatial and temporal convolutions to extract coordination patterns between joints and frames.
Attention Pooling & Regression Head: Utilizes a temporal attention module to highlight significant motion segments and employs a lightweight MLP regressor to output the final human-likeness score.
Training Objective: PTR-Net is optimized using an L2 regression loss function and includes a regularization term to ensure the smoothness and stability of motion evaluation.
L = L = L_score + λ * L_reg.
Qualitative Evaluation

Four representative motion examples with PTR-Net predictions compared to human-annotated scores.

To examine the generalization ability of our benchmark beyond the distribution of the collected data, we further tested it on motions from unseen humanoid robots, including the recently released (Nov. 2025) XPeng IRON as shown in figure.
PTR-Net predicts an outstanding performance of the XPeng IRON human-likeness score of 4.25, closely matching the human annotation average of 4.36.
Experiments
In this section, we evaluate the performance of the proposed baseline and others on the motion human-likeness task. we employ three complementary metrics: Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and Spearman’s Rank Correlation to evaluate.
Comparison of VLM Assessment Baselines
PTR-Net significantly outperforms existing VLMs (including Gemini 2.5 Pro and Qwen3-VL-Plus) and benchmark models like MotionBERT on the Robot Motion Turing Test benchmark, demonstrating lower MAE (Mean Absolute Error) and RMSE (Root Mean Square Error), as well as a higher Spearman correlation coefficient.
Human-imitating-humanoid Subset
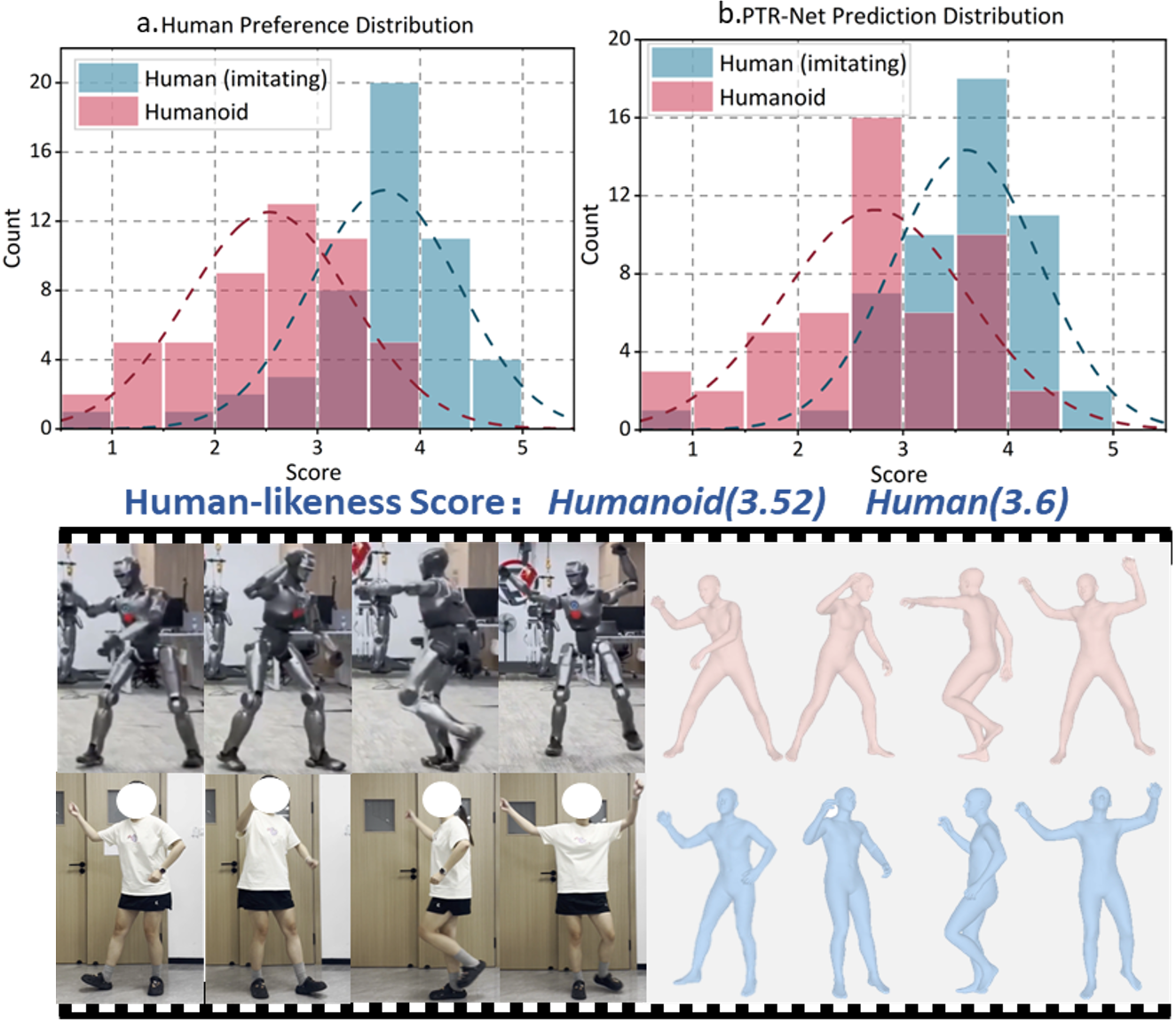
We analyze the human-imitating-humanoid subset to examine evaluation boundaries of motion human-likeness. As shown in figure, PTR-Net closely follows human annotators’ distributions, suggesting its ability to capture subtle temporal and coordination cues. Human ratings show partial overlap between imitating humans and humanoids, indicating that intentional imitation can blur the evaluation boundary of human-likeness.
Conclusion
In this work, we introduce the Motion Turing Test and HHMotion dataset, a comprehensive benchmark of humanoid and human motions annotated by 30 annotators. Despite advances, robots still lag in complex actions. Our PTR-Net baseline effectively predicts motion human-likeness, outperforming existing VLM models and serving as a tool for evaluation and reinforcement learning. Together, they provide a rigorous, human-centered foundation for developing more natural and expressive humanoid motions.
Citation
@inproceedings{Li2026Towards,
title={Towards Motion Turing Test: Evaluating Human-Likeness in Humanoid Robots},
author={Mingzhe, Li and Mengyin, Liu and Zekai, Wu and Xincheng, Lin and Junsheng, Zhang and Ming, Yan and Zengye, Xie and Changwang, Zhang and Chenglu, Wen and Lan, Xu and Siqi, Shen and Cheng, Wang},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
year={2026}
}