
Abstract
Human Motion Recovery (HMR) research mainly focuses on ground-based motions such as running. The study of capturing climbing motion, an off-ground motion with frequent contact and extreme joint configurations, is sparse. This is due to the limited availability of large-scale and challenging 3D-labeled climbing datasets, and the lack of anatomically meaningful representations that support stable kinematic and biomechanical analysis. To recover human climbing motions from skeletal representations, we propose ClimbingCap++, a global climbing motion recovery method that reconstructs continuous 3D human motion in both camera and world coordinates. ClimbingCap++ introduces a skeleton optimization module that regularizes the recovered motions toward anatomically consistent joint structures, improving stability and physical plausibility under extreme poses. To support this task, we collect ClimbingText, a large-scale and challenging multi-modal climbing dataset with time-synchronized RGB, LiDAR, and IMU measurements, accurate 3D motion labels, and global trajectories. ClimbingText provides anatomically consistent skeleton representations and segment-level semantic descriptors to facilitate interpretation for training and rehabilitation. Finally, we develop ClimbingAnalysis, an end-to-end analysis platform that connects motion capture, skeleton-aware kinematic and biomechanical analysis, and human-understandable reporting for training and rehabilitation workflows. We demonstrate the quality of ClimbingText and present strong results from ClimbingCap++ on challenging climbing scenarios.
Introduction
Global Human Motion Recovery (HMR) remains challenging due to the complexity of human poses and dynamic interactions between humans and their environments. Existing methods mainly focus on recovering ground-based motions such as walking, dancing, and running using RGB images, LiDAR point clouds, or IMUs.
Unlike ground-based motions, climbing is an off-ground activity characterized by frequent human-scene contacts, severe occlusions, extreme limb extensions, and long-term vertical movements. Existing climbing datasets such as SPEED21 and CIMI4D are limited in either dimensionality, motion complexity, or scale, preventing robust understanding of challenging climbing motions.
To address these limitations, we introduce:
-
ClimbingCap++:
A multimodal global HMR framework for climbing that jointly reconstructs camera-space and world-space motions while enforcing anatomical consistency through skeleton optimization. -
ClimbingText:
A large-scale multimodal climbing dataset with anatomically consistent skeleton annotations and motion-language semantics for training and rehabilitation analysis. -
ClimbingAnalysis:
A practical end-to-end climbing motion analysis platform supporting anatomy-aware interpretation, structured reporting, and evidence-based training and rehabilitation guidance.
Method: ClimbingCap++
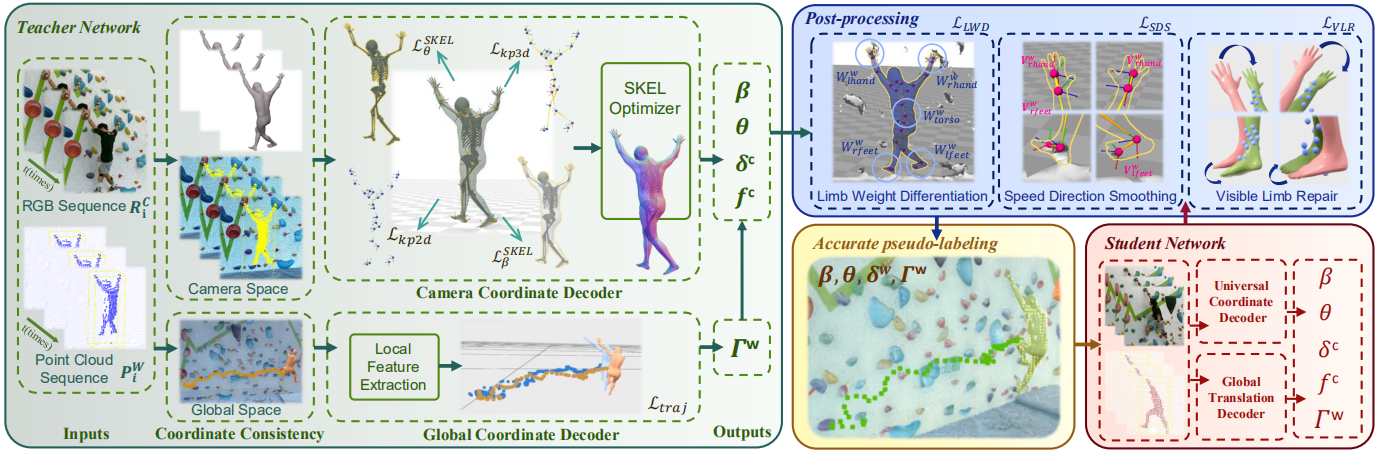
Climbing motion capture is challenging due to extreme limb extensions, severe self-occlusions, frequent human-wall interactions, and long-term global motion drift. To tackle these issues, ClimbingCap++ adopts a structured pipeline consisting of:
- Multimodal Feature Extraction
- Separate Coordinate Decoding
- Anatomical Skeleton Optimization
- Post-processing Refinement
- Semi-supervised Teacher-Student Training
Multimodal Feature Extraction
ClimbingCap++ takes synchronized RGB images and LiDAR point clouds as input. RGB images are processed using a ViT-based backbone, while point clouds are encoded using PointNet++ with temporal modeling modules.
The extracted visual and geometric features are fused into a shared spatiotemporal representation for downstream decoding.
Separate Coordinate Decoding
ClimbingCap++ separately predicts:
- Camera-space body configuration
- World-space global trajectories
The camera coordinate decoder reconstructs body pose, shape, and camera translation, while the world coordinate decoder estimates global translation trajectories.
Coordinate consistency constraints are introduced to ensure that motions reconstructed in camera and world coordinates remain physically consistent.
Anatomical Skeleton Optimization
To improve anatomical consistency under extreme climbing poses, ClimbingCap++ incorporates the SKEL anatomical skeleton model.
The optimization module regularizes:
- Anatomically meaningful joint structures
- Stable joint rotations
- Soft range-of-motion constraints
- Depth consistency
This anatomy-aware optimization improves:
- Physical plausibility
- Joint stability
- Long-term temporal consistency
- Biomechanical interpretability
Post-processing
The post-processing stage refines recovered motions using:
- Limb Weight Differentiation Loss (LLWD)
- Speed Direction Smoothing Loss (LSDS)
- Visible Limb Repair Loss (LVLR)
These losses leverage LiDAR geometry and scene constraints to improve global consistency and recover difficult limb movements.
Semi-supervised Training
To leverage large-scale unlabeled climbing data, we adopt a teacher-student semi-supervised learning framework.
The teacher model generates refined pseudo-labels from unlabeled sequences, while the student model learns from these pseudo-labels to improve robustness under severe occlusions and challenging contact-rich motions.
The ClimbingText Dataset
ClimbingText is a large-scale multimodal motion-language dataset designed for global human motion recovery and climbing motion understanding.
It captures complex climbing motions involving:
- Frequent contact transitions
- Large vertical displacements
- Severe occlusions
- Multi-directional body movements
The dataset contains:
- 459K synchronized frames
- 398 sequences
- 32 skilled climbers
- 15 real-world climbing scenes
Each sample includes:
- RGB images
- LiDAR point clouds
- IMU measurements
- Global motion annotations
- Anatomical skeleton representations
- Motion-language semantic descriptions
Hardware and Configuration
The acquisition system integrates:
- Ouster-OS1 LiDAR
- 1080P RGB cameras
- Xsens MVN IMU system with 17 sensors
- High-resolution scene scanners
All sensor streams are synchronized and aligned into a unified world coordinate system.
Annotation Pipeline
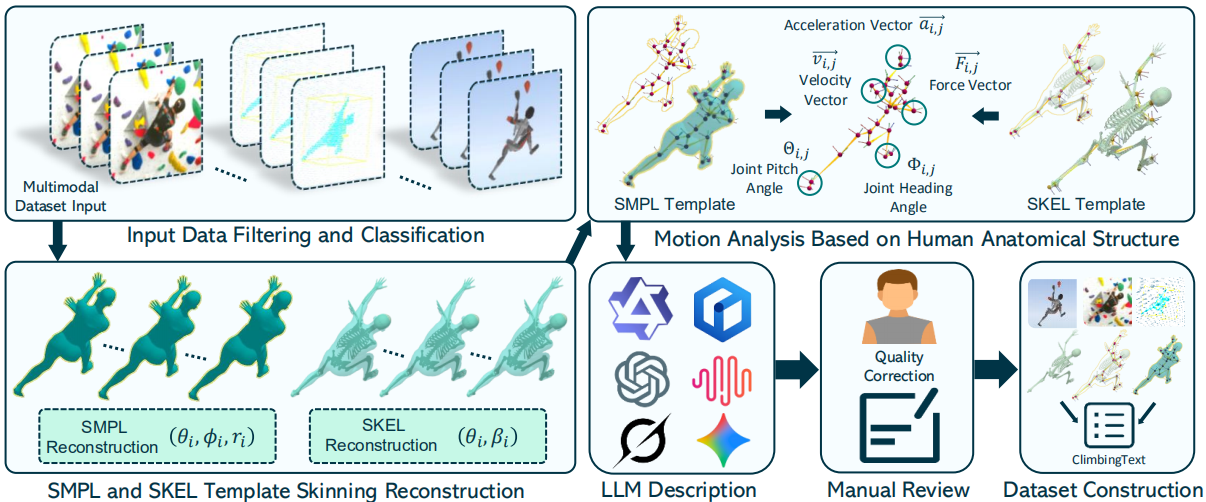
The annotation pipeline consists of three stages:
Multi-modal Data Preprocessing
- Time synchronization using PTP
- Spatial calibration among RGB, LiDAR, and IMU
- Global coordinate alignment
Multi-stage Global Optimization
The optimization stage introduces:
- Global Refit Loss (LGR)
- Scene Touch Loss (LST)
to refine motion alignment with the scene geometry and prevent unrealistic body-scene intersections.
Manual Repair and Verification
Four annotators manually refine ambiguous poses and propagate key-frame corrections to ensure smooth and physically plausible annotations.
Motion-Language Construction
ClimbingText additionally provides motion-language annotations for training and rehabilitation analysis.
The framework includes:
- Motion segmentation and filtering
- Dual reconstruction using SMPL and SKEL
- Anatomy-aware motion analysis
- LLM-based description generation and quality control
Anatomy-aware Motion Analysis
Based on reconstructed anatomical skeletons, we compute:
- Joint velocity
- Joint acceleration
- Motion saliency
- Trajectory curvature
- Posture entropy
- Force-related indicators
These features are serialized into structured motion tokens for downstream language modeling.
LLM-based Motion Description
Large language models generate climbing-aware descriptions from motion features, summarizing:
- Body coordination
- Support transitions
- Joint interactions
- Motion intent
- Spatial relationships
All generated descriptions are manually verified to ensure accuracy and consistency.
ClimbingAnalysis Platform

We develop ClimbingAnalysis, a practical training and rehabilitation platform that bridges:
- Motion capture
- Anatomy-aware analysis
- Retrieval-augmented reasoning
- Human-understandable reporting
Core Components
ClimbingRAG
A retrieval-augmented generation system retrieving evidence-backed knowledge for climbing analysis.
ClimbingBench
A benchmark evaluating:
- Training reasoning
- Injury analysis
- Rehabilitation planning
- Safety reasoning
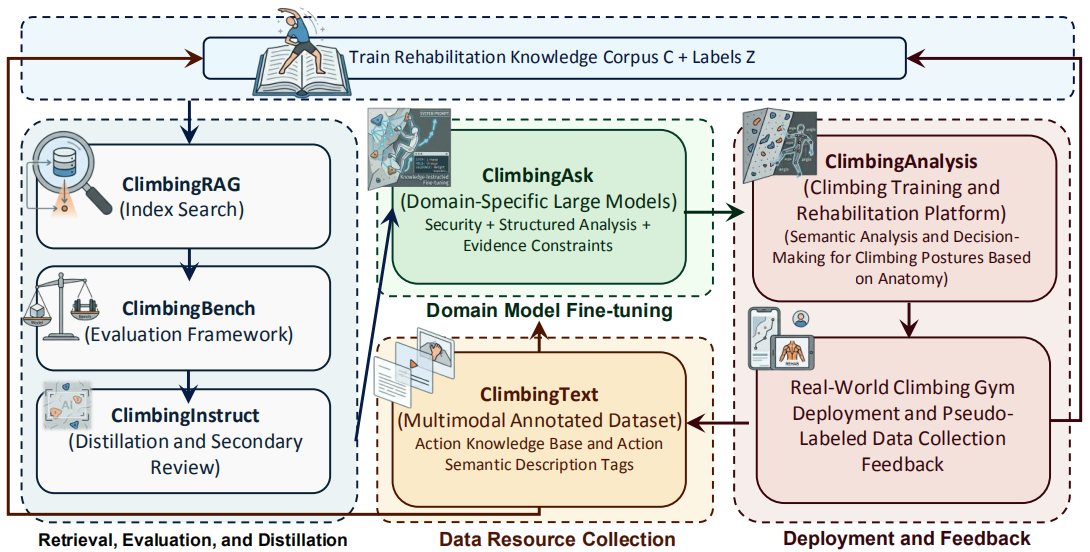
ClimbingAsk
A domain-specific large language model fine-tuned for climbing training and rehabilitation tasks.
Web Deployment
The final platform generates:
- Structured reports
- Motion analysis summaries
- Risk warnings
- Rehabilitation suggestions
- Evidence-backed explanations
The platform additionally supports continuous feedback and data updates through real-world deployment.
Experiments
Dataset Evaluation
We evaluate the annotation quality of ClimbingText using:
- MPJPE
- PA-MPJPE
- PVE
- Acceleration Error
The optimization constraints significantly improve annotation quality and scene consistency.
Comparison on Global Motion Recovery
We compare ClimbingCap++ with multiple state-of-the-art HMR methods across:
- RGB-based methods
- LiDAR-based methods
- RGB+LiDAR multimodal methods
ClimbingCap++ achieves superior performance in both:
- Camera coordinate metrics
- World coordinate metrics
especially in challenging vertical climbing scenarios.
Generalization on CIMI4D
ClimbingCap++ also demonstrates strong generalization on the CIMI4D dataset without fine-tuning.
Ablation Study
We analyze the contributions of:
- Anatomical optimization
- Semi-supervised learning
- Coordinate consistency
- Post-processing losses
The results demonstrate that anatomical optimization and multimodal reconstruction are crucial for stable climbing motion recovery.
Conclusion
We propose:
- ClimbingCap++, an anatomy-consistent global climbing motion recovery framework
- ClimbingText, a large-scale multimodal climbing motion-language dataset
- ClimbingAnalysis, a practical training and rehabilitation analysis platform
ClimbingCap++ reconstructs anatomically consistent human climbing motions in both camera and world coordinates while improving physical plausibility and long-term stability.
ClimbingText introduces large-scale multimodal annotations together with anatomy-aware motion semantics, enabling future research in motion reconstruction, biomechanics, and training analysis.
ClimbingAnalysis bridges motion capture and human-understandable reasoning for real-world climbing training and rehabilitation workflows.