Abstract
Human motion follows a temporal hierarchical structure, transitioning from low-frequency global trajectories to high-frequency details. Inspired by the success of multi-level autoregressive models in computer vision, we propose MotionMAR, a coarse-to-fine framework for motion reconstruction from sparse observations. It first estimates the global trajectory of human motion and then gradually refines the temporal details. This architecture consists of four integrated components. The Temporal Multi-scale Tokenization (TMT) VQ-VAE encodes the data at multiple temporal resolutions, separating semantic motion from minor jitters. The Motion Autoregressive Network (MAN) operates in this latent space, predicting motion across scales. It first establishes the global structure through coarse indices and then generates finer indices to recover specific details. Meanwhile, the Scale-Aware Control (SAC) module integrates sparse tracking data to ensure the generated output aligns with actual observations. The Motion Refinement Network (MRN) subsequently smooths consecutive poses and eliminates quantization artifacts. Experiments show that MotionMAR achieves state-of-the-art accuracy on the AMASS dataset, providing a reliable and structure-aware approach for motion reconstruction.
Introduction
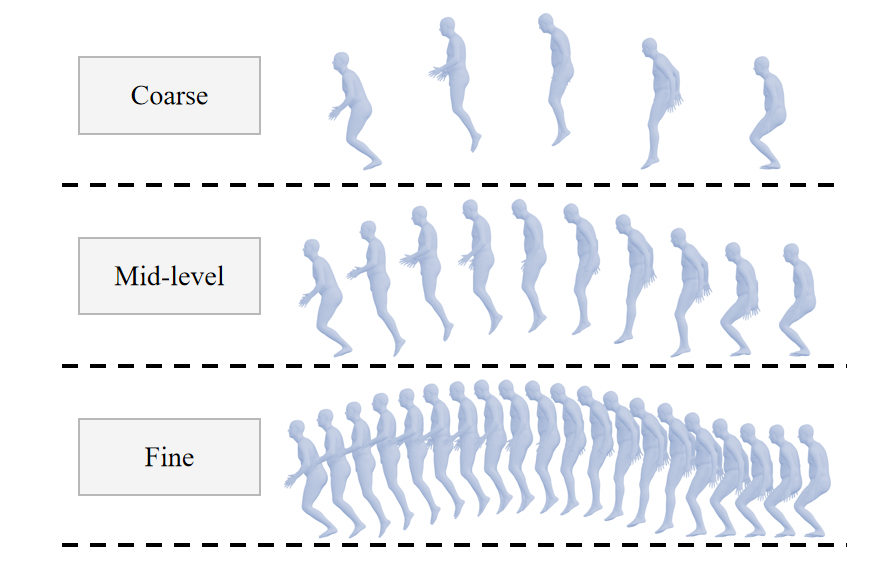
Human motion naturally follows a multi-level structure over time. Whether a casual walk or an expressive dance, a motion sequence is not just a flat series of joint positions. Rather, it is a multi-scale composition driven by intent, ranging from broad, low-frequency trajectories to quick, high-frequency details. This coarse-to-fine structure means that broader trends naturally guide the finer details, ensuring the final motion is both meaningful and fluid.
However, traditional modeling methods often overlook this natural characteristic. They typically treat motion data as a flat sequence of frames or tokens, processing every time-step at a single scale. This limitation becomes especially obvious when dealing with sparse observations—such as inputs limited to VR headsets and controllers—where the model must reconstruct complex full-body dynamics from minimal data.
To bridge this gap, we introduce a new perspective by applying Visual Autoregressive (VAR) modeling—a generative framework known for its coarse-to-fine approach—to align directly with the temporal nature of human motion. Guided by this connection, we propose MotionMAR, a multi-scale autoregressive framework designed to reconstruct high-quality human motion from sparse observations.
Method: MotionMAR
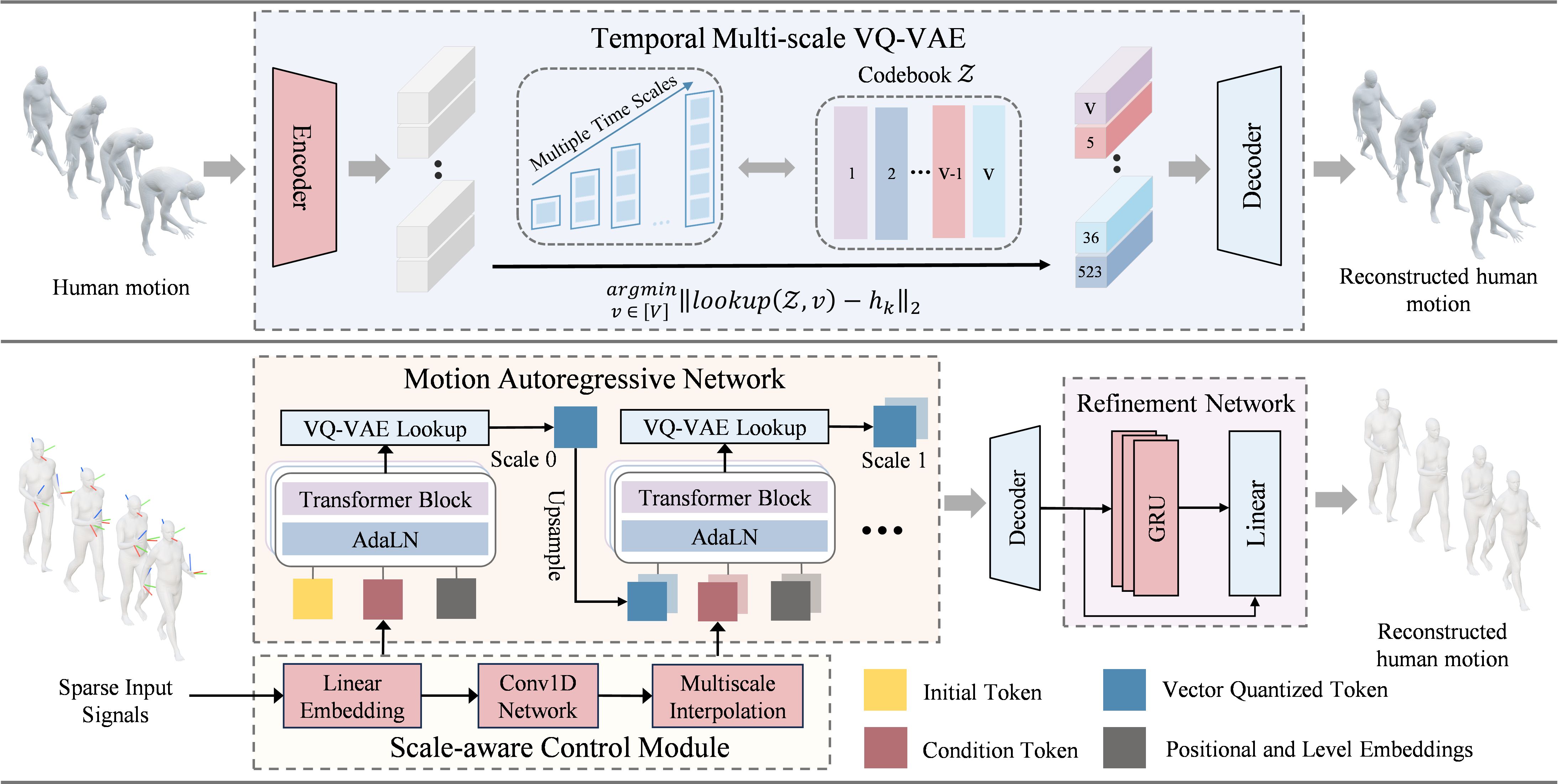
Temporal Multi-scale VQ-VAE (TMT VQ-VAE)
Unlike the spatial scaling used in standard VAR, our model defines quantization scales based on time resolutions. The encoding process structures the motion across multiple scales, beginning with coarse, low-frequency representations that map out the global trajectory and gradually expanding into finer, high-frequency details. This successfully separates broad semantic motion from minor jitters, maintaining strong temporal connections across different scales.
Motion Autoregressive Network (MAN) & Scale-aware Control (SAC)
Once the motion is mapped into a discrete temporal pyramid, the MAN takes over as the generative core. Conditioned solely on augmented sparse observations, MAN reconstructs the full motion sequence by progressively sampling indices from this latent space across temporal layers. To ensure the generated output aligns with actual observations, the SAC Module dynamically adjusts the network’s conditioning at each scale. It synchronizes the conditioning signal with the token sequence length at every scale through temporal alignment, providing both local scale-wise guidance and global context modulation.
Motion Refinement Network (MRN)
Decoding these indices back into poses via the VQ-VAE often introduces quantization artifacts and temporal jitter. To resolve this, a MRN operates directly on the continuous pose sequence. Functioning as a temporal stabilizer, this multi-layer Bidirectional Gated Recurrent Unit (Bi-GRU) aggregates temporal context from past and future frames to correct geometric inconsistencies and ensure fluid physical accuracy.
Experiments
To evaluate MotionMAR, we tested its ability to reconstruct full-body motion from sparse tracking signals (head and hands) simulating a typical VR/XR environment. We used the AMASS dataset, assessing our approach across three distinct settings (S1, S2, and S3).
Qualitative Experiments for MotionMAR
Quantitative Results
MotionMAR significantly outperforms existing methods across representative paradigms, including Optimization-based (Final IK), VAE-based (VAE-HMD), Transformer-based (AvatarPoser, AvatarJLM), Diffusion-based (AGRoL, SAGE), and other Autoregressive models (MAGE, HiPART, RPM).
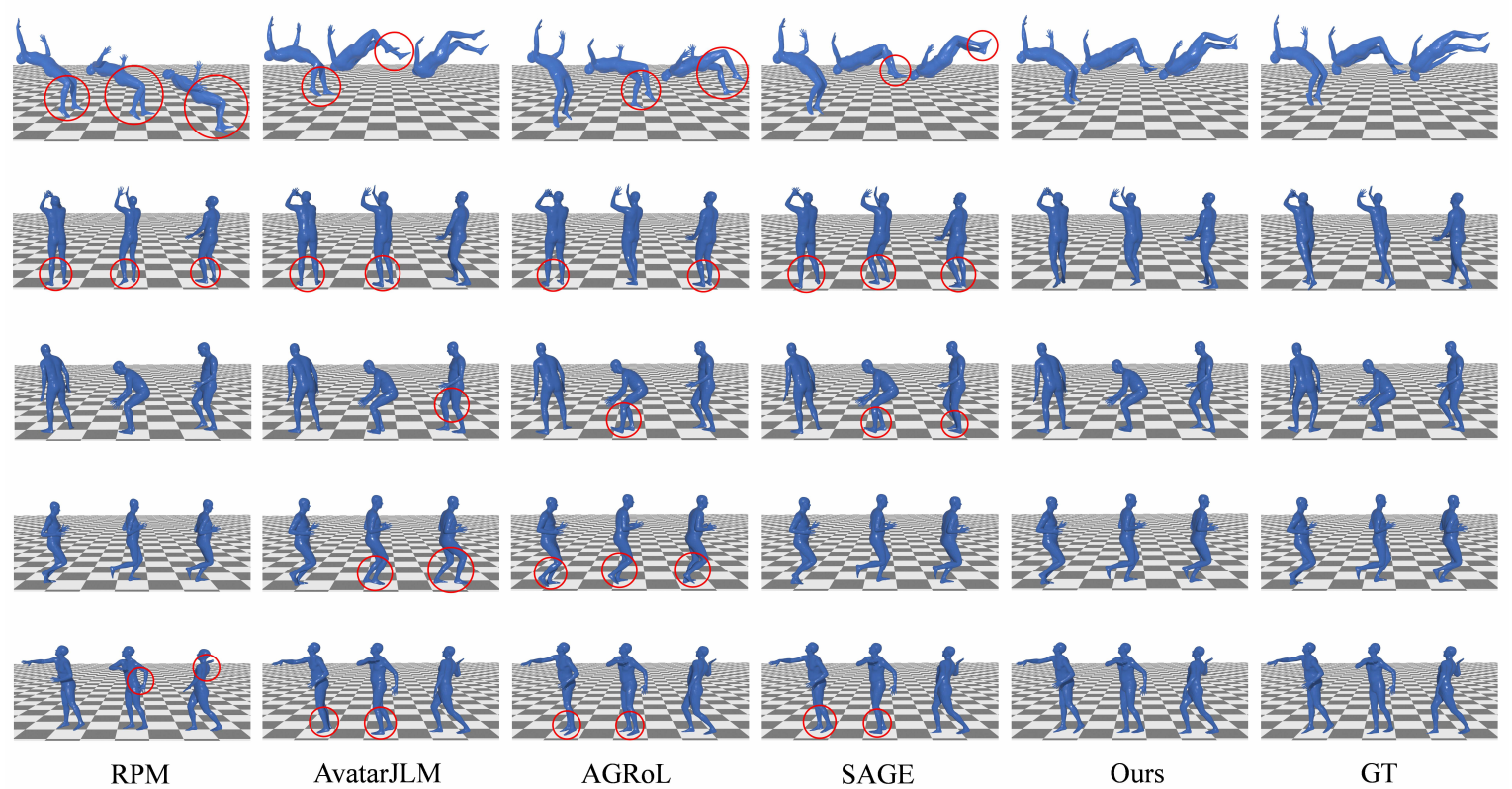
Our method achieves state-of-the-art accuracy in Mean Per Joint Rotation Error (MPJRE) and Mean Per Joint Position Error (MPJPE). Specifically, MotionMAR excels in capturing both structural human pose and coherent full-body motion, exhibiting robust consistency with ground truth (GT) data.
Complexity and Efficiency
MotionMAR achieves a compelling balance between model complexity and runtime performance. With only 42.36M parameters and 1.47G FLOPs, our model delivers an inference speed of 61.76 FPS. This performance comfortably exceeds standard real-time thresholds required for practical online VR/AR deployment, significantly outperforming heavy diffusion-based models like SAGE.
Conclusion
We introduce MotionMAR, a multi-scale autoregressive framework for human motion reconstruction that explicitly models the intrinsic temporal hierarchy of human kinematics. By adopting a temporal coarse-to-fine strategy, MotionMAR progressively refines motion from global low-frequency trajectories to local high-frequency dynamics. Extensive experiments demonstrate that MotionMAR achieves superior reconstruction accuracy, temporal consistency, and robustness, providing a principled and biologically inspired solution for motion modeling in VR/AR applications.
Citation
```bibtex @inproceedings{luo2026motionmar, title={MotionMAR: Multi-scale Auto-Regressive Human Motion Reconstruction from Sparse Observations}, author={Luo, Yuhua and Zhang, Junsheng and Liu, Mengyin and Lin, Xincheng and Yan, Ming and Chen, Zhudi and Wen, Chenglu and Xu, Lan and Shen, Siqi and Wang, Cheng}, booktitle={Proceedings of the 43rd International Conference on Machine Learning}, year={2026} }